1. Sklearn API介绍
本小节使用 scikit-learn 的 KNN API 来完成对鸢尾花数据集的预测.
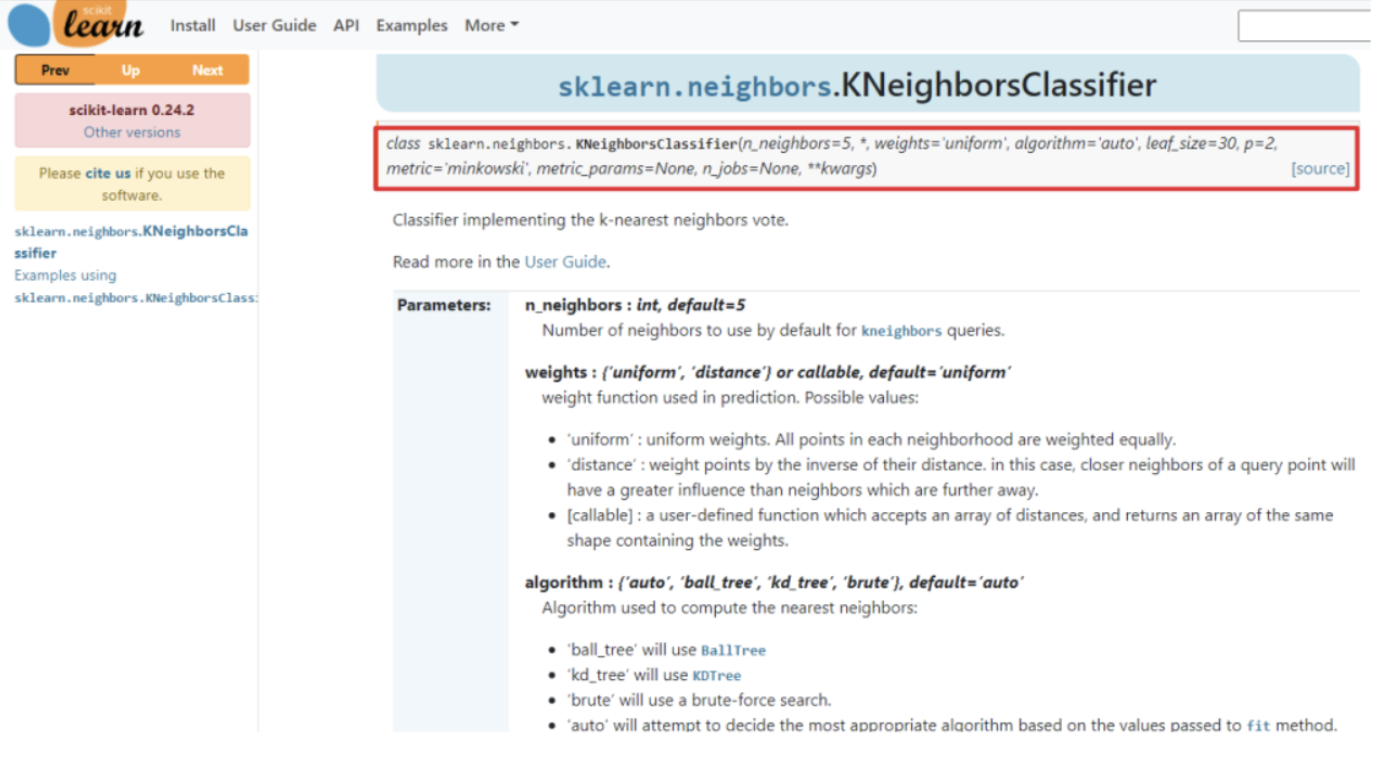
API介绍
2. 鸢尾花分类示例代码
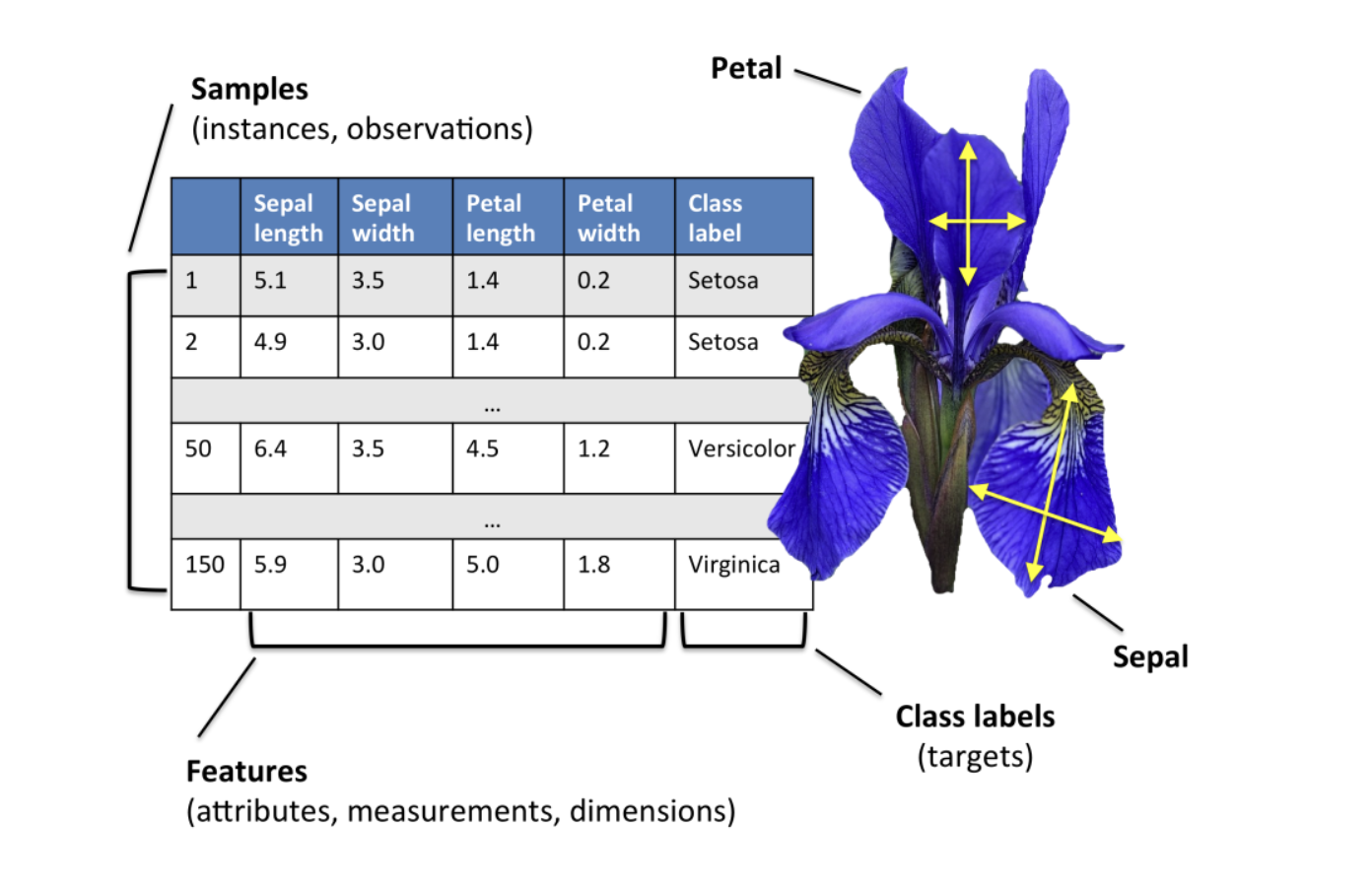
鸢尾花数据集
鸢尾花Iris Dataset数据集是机器学习领域经典数据集,鸢尾花数据集包含了150条鸢尾花信息,每50条取自三个鸢尾花中之一:Versicolour、Setosa和Virginica

每个花的特征用如下属性描述:
示例代码:
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
if __name__ == '__main__':
# 1. 加载数据集
iris = load_iris() #通过iris.data 获取数据集中的特征值 iris.target获取目标值
# 2. 数据标准化
transformer = StandardScaler()
x_ = transformer.fit_transform(iris.data) # iris.data 数据的特征值
# 3. 模型训练
estimator = KNeighborsClassifier(n_neighbors=3) # n_neighbors 邻居的数量,也就是Knn中的K值
estimator.fit(x_, iris.target) # 调用fit方法 传入特征和目标进行模型训练
# 4. 利用模型预测
result = estimator.predict(x_)
print(result)
3. 小结
1、sklearn中K近邻算法的对象:
from sklearn.neighbors import KNeighborsClassifier
estimator = KNeighborsClassifier(n_neighbors=3) # K的取值通过n_neighbors传递
2、sklearn中大多数算法模型训练的API都是同一个套路
estimator = KNeighborsClassifier(n_neighbors=3) # 创建算法模型对象
estimator.fit(x_, iris.target) # 调用fit方法训练模型
estimator.predict(x_) # 用训练好的模型进行预测
3、sklearn中自带了几个学习数据集
- 都封装在sklearn.datasets 这个包中
- 加载数据后,通过data属性可以获取特征值,通过target属性可以获取目标值, 通过DESCR属性可以获取数据集的描述信息